用LSTM预测村尺度玉米产量
Predicting County Level Corn Yields Using Deep Long Short Term Memory Models
论文全文:https://arxiv.org/abs/1805.12044
利用村级别的玉米产量数据和小时级别的气象站点数据在一个省规模的区域训练LSTM来估产,对比USDA的调查数据做验证。几个很有趣的点记录如下。
- 1964年USD就开始根据实地调研数据对美国玉米产量的数据进行预测。中间使用各种方法,包括遥感等。但是在2017年的秋天,仍旧是基于调查数据做预测。
- 商业估产的公司已经不少,
- 2008年 7个影响玉米产量的因素(The Seven Wonders of the Corn Yield World),气象因子占据绝对。而其中,雨,温度,风和湿度则是决定性因素。
- 温度是非线性效应(nonlinear effect on corn yeild)。这是一篇发表再nature的上的文章,也是我对温度建立一个初步认知的开始。
- 文章对产量数据做了一个处理,收集了1980-2016年的Iowa周玉米产量数据,但是每年玉米的增产存在一部分的遗传获益效应(genetic gain)。文章根据前人的研究成果做了降趋势处理(de-trend 每年1.5%的增长效应)。
- 气象数据是气象站点(买的=。=),19x19 mile一个气象站点。
- Growing Degree Days(GDDs),业界专家使用的一个指标,我理解其实应该是活动积温。当天最大温度+当天最低温度 均值 减去 玉米能生长的基础温度。
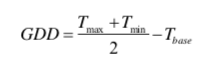
- 生育期用的4月到10月,如果时间序列小时尺度的话t=5136,用天的话t=214。文章的train sample 只有3267个点,估t=5136话参数实在是太多了。所以还是用了天。但是这里如果有实际的生育期数据,t估计会小很多。用小时就可能了。
- Baseline 用了所有可用的变量,模型预测直接成了一条线。文章给出的理由是这些变量并不是独立的。
- training用了keras。有想法之后用再高阶API训练真是效率。红线是真实值,黑线是预测值。调正过的2013年的模型效果还是很不错的。
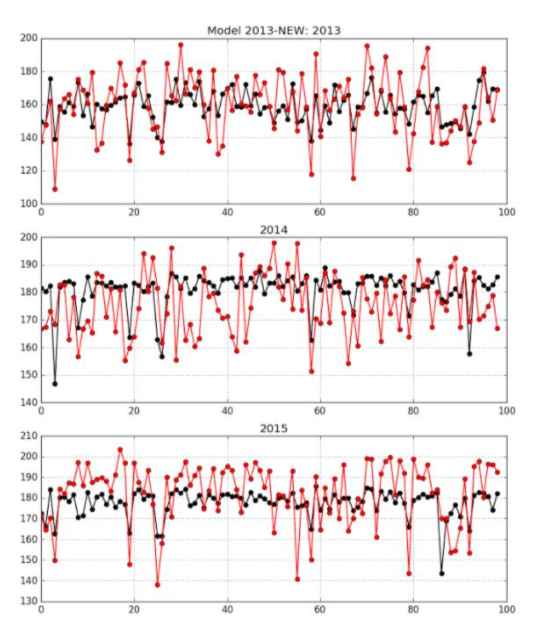
- 结果的地方,文章用了2013年的模型,很好的预测了2014和2015,但是在2016的时候,模型的结果整体低于实际值。这里一个思路转化的很好,不应该想去模型是不是有问题,而是考虑这一年是不是存在着一些不同的情况(which indicateing that the weather event in 2016 were not represented in the historical data)。多年都是对的在某一年不一样。是不是这一点存在极端情况(extreme case)。
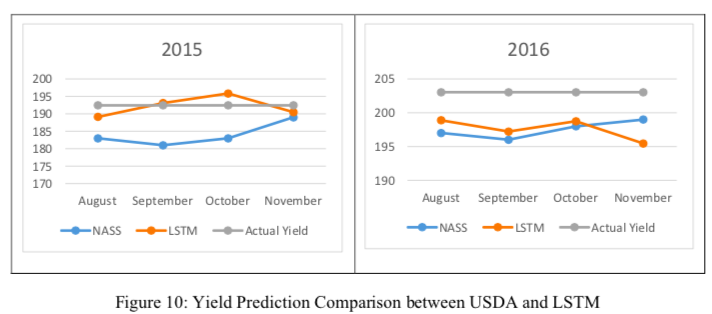
- 因为USDA是在8,9,10,11月发布产量预测报告,文章最后按照这个时间序列做了对比。效果确实不错。虽然都不准,但是总体看比调查数据准确度还是高一些。